Migration form AWS RDS to Supabase!

Introduction
AWS is synonymous with cloud services such as servers, databases, and infrastructure, and is beloved by many companies and developers. For students as well, AWS usage is often recommended for school projects, and since many course materials use AWS as examples, it becomes relatively familiar to approach. However, the situation is not so favorable for small projects, teams composed of developers without deep server knowledge, and toy projects. Due to countless configuration settings, cascading network knowledge requirements, and unexpected cost explosions, it is also true that many developers are increasingly reluctant to use AWS.
I too had examples given by professors during my undergraduate years that were AWS-based, and naturally proceeded with most school projects using AWS. However, while I repeatedly faced many problems, I judged that realistic alternatives were lacking and continued to study AWS consistently. But due to continuous billing explosions and the requirement for high-level network knowledge, I planned to migrate from AWS to a new service.
Considering the aforementioned reasons, one of the notable alternatives is Supabase. For simple services, toy projects, and those who can start completely free, Supabase has been steadily increasing its user base since 2022 and appears to provide a stable environment by attracting investments of over 150 billion won. Additionally, it has recently become known that specific projects of large corporations were developed using Supabase, and through Supabase's continuous updates, additional APIs such as Auth are being developed beyond just DB.
I am also currently using Supabase for various projects including this blog and am experiencing that it is more convenient than AWS. Through this post, I will cover the advantages and points to be mindful of regarding Supabase that I discovered while changing technology from AWS RDS and S3 to Supabase.
Supabase Trend
Looking at RDBMS rankings, Oracle and MySQL are the undisputed 1st and 2nd places. In fact, if you look at many clone codes and tutorial-based courses, you can easily find projects being conceived using MySQL.
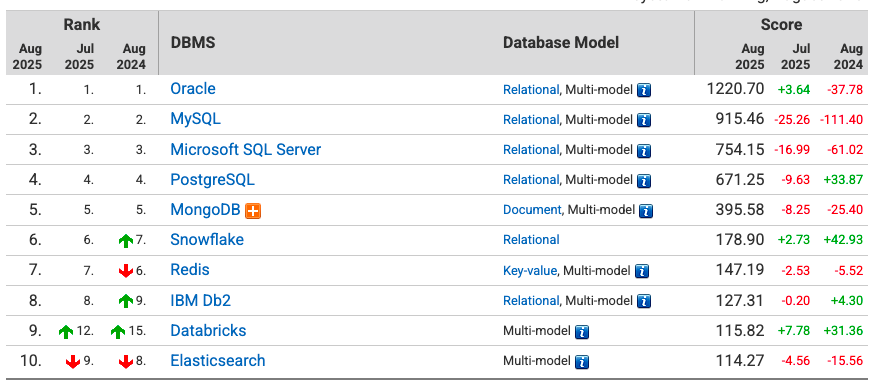
However, Supabase manages data based on PostgreSQL, not MySQL. One of AWS's biggest advantages is unlimited freedom for developers. RDS also has the advantage that developers can select and use various DBs such as MariaDB and MySQL, but in contrast, Supabase has the disadvantage of being fixed to PostgreSQL. If you are a developer who has only used MySQL at a shallow level, there would be no major issue when migrating to PostgreSQL, but I think it would not be easy for those with very deep knowledge and experience in one side, or those dealing with deep technologies of specific DBs to move to the other side. Personally, since I was only using simple functions of MySQL, there was no major problem in moving to Supabase PostgreSQL.
Supabase's Simple Configuration
I was using AWS for all backend servers of my previous blog. AWS RDS and S3 were representative among them, and I tried to optimize costs with appropriate instance types and settings, but it was not easy. For RDS, basic settings such as Multi-AZ deployment, automatic backup, and performance monitoring were activated, and also EC2s hidden everywhere, RDS instances that I thought were deleted were still alive, and of course not just RDS charges, but eventually more than $80 was generated in a toy project. Due to the nature of toy projects where I had to handle all parts alone, I couldn't check all configuration items thoroughly and faced this worst result.
But Supabase is simple.
After creating one Supabase project and creating db tables inside the project according to the project being developed, RDBMS connection preparation was complete. Of course, external communication that was done in Lambda would require additional backend logic, but since the developed logic can directly interact with external logic, the Lambda and NatGate problem could also be perfectly solved. This simplicity was clearly evident in the actual code as well.
Actual Code Migration
Previously, I used MySQL and developed APIs by directly writing Raw Queries in the backend. This was due to my own philosophy of avoiding becoming a developer who only uses ORM without understanding SQL.
However, recently while migrating to Supabase, I came to refactor code by introducing the ORM officially supported by Supabase.
For MySQL, basic settings such as connection pooling and connection configuration are necessary. MySQL communicates through connections, and connections are managed within pooling. If available connections are insufficient, users must wait, and conversely, if connections are created excessively and not used, network delays or resource waste can occur. Therefore, appropriate connection pooling and connection management are essential.
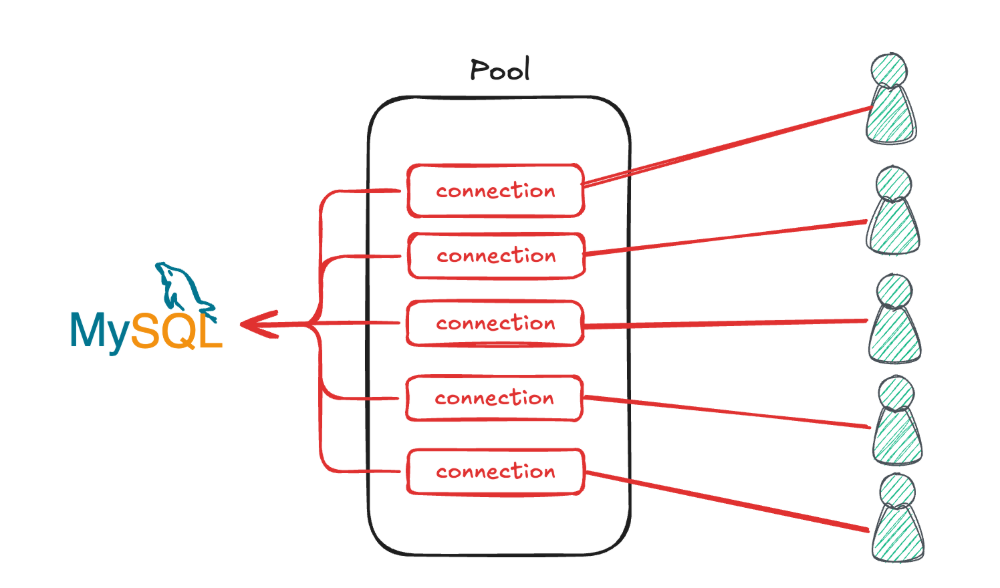
For this, various setting values such as connection limit, connectionTimeout, maxIdle, idleTimeout must be specified, and when network requests or API requests occur, connections must be pulled from the pool to handle connections. Through these settings, system resources can be managed efficiently and stable API response speed can be maintained.
export const getPool = () => {
if (!pool) {
pool = mysql.createPool({
host: process.env.DB_HOST_DIR,
user: process.env.DB_USER,
password: process.env.DB_PASSWORD,
database: process.env.DB_NAME,
waitForConnections: true,
connectionLimit: 10, // Maximum number of connections
queueLimit: 0,
connectTimeout: 10000,
maxIdle: 5,
idleTimeout: 30000,
});
}
return pool;
};
export async function executeQuery<T>(sql: string, values?: any[]): Promise<T> {
return executeWithRetry(async () => {
const connection = await getPool().getConnection();
try {
await connection.ping(); // Check connection status
const [rows] = await connection.query(sql, values || []);
return rows as T;
} finally {
connection.release(); // Return connection
}
});
}
Like this, developers must directly manage connection pool size, timeout, and retry logic. If settings are wrong, users may wait due to connection shortage, or conversely, resource waste due to excessive connections may occur.
Once such configuration is complete, you are finally ready to develop REST APIs.
export async function GET(req: NextRequest) {
const email = req.nextUrl.searchParams.get("email");
if (!email) {
return NextResponse.json({ error: "Email is required" }, { status: 400 });
}
try {
const sql = "SELECT * FROM User WHERE email = ?";
const result = await executeQuery(sql, [email]);
if (!Array.isArray(result) || result.length === 0) {
return NextResponse.json({ error: "User not found" }, { status: 401 });
}
return createResponse(req, result[0]);
} catch (err) {
return handleError(err);
}
}
Even composing a very simple REST API requires quite deep knowledge and practice. While it has very high flexibility to ensure applicability and stability, high flexibility can be a double-edged sword as it can give developers higher responsibility and constraints.
However, Supabase "automatically" adjusts Pool and Connection internally according to project size and number of visitors. In other words, there are not many parts that developers need to directly care about. At this time, the part that is "automatically" adjusted is not something that developers need to heavily debug unless actual problems occur, and when problems do occur, development can proceed in the direction of tracking the internal structure to find problems and adding settings.
When Supabase says it "manages automatically," the following technologies actually work internally:
1. pgBouncer-based Connection Pooling
Supabase uses pgBouncer, a lightweight Connection Pooler for PostgreSQL. Transaction Pooling
reuses connections per transaction unit, Session Pooling manages connections per session unit, and Statement Pooling performs optimization per SQL statement unit.
2. Auto-scaling Connection Pool
// Things that need to be manually configured in AWS
connectionLimit: 10,
maxIdle: 5,
idleTimeout: 30000,
// Things automatically handled in Supabase
- Dynamic Pool size adjustment through traffic pattern analysis
- Connection allocation considering regional load balancing
- Automatic tuning based on real-time performance monitoringIn AWS, you need to manually set connectionLimit, maxIdle, idleTimeout, etc., but in Supabase, dynamic Pool size adjustment through traffic pattern analysis, Connection allocation considering regional load balancing, and automatic tuning based on real-time performance monitoring are automatically handled.
3. Health Check & Auto-recovery
Connection Validation periodically verifies connection status, and Dead Connection Detection automatically
detects and removes disconnected connections. It also uses Circuit Breaker Pattern to automatically block connections during failures and recover them.
4. Query Optimization
Prepared Statement Caching caches execution plans for frequently used queries, and Index Hint performs
automatic optimization linked with PostgreSQL's query planner. Query Routing manages read/write distributed processing.
Understanding that such internal structure exists, if you create REST APIs with basic settings, you first create a project in Supabase and bring the key that exists inside the project to define the Supabase object.
const supabaseURL = process.env.NEXT_PUBLIC_SUPABASE_URL!;
const supabaseServerKey = process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY!;
export const supabase = createClient(supabaseURL, supabaseServerKey);
And then you just use it directly.
export async function GET(req: NextRequest) {
const email = req.nextUrl.searchParams.get("email");
if (!email) {
throw new Error("Email is required");
}
try {
const { data, error } = await supabase
.from("user")
.select("*")
.eq("email", email);
return createResponse(req, data);
} catch (err) {
return handleError(err);
}
}
While there is the inconvenience of having to master Supabase's internal functions similar to ORM to use it, it is quite intuitive and convenient to use, so it doesn't take long to master, and I also took less than two days to change all APIs to match Supabase when migrating from AWS RDS MySQL to Supabase.
Comparing Supabase's configuration file with MySQL's configuration file, there are significant differences in length, configuration elements, complexity, etc., so it is certain that there is convenience for developers. Of course, various settings such as Retry and TimeOut can be added in Supabase according to developer's discretion, but the fact that Pool and Connection are adjusted within Supabase itself is a very big advantage from the developer's perspective.
The advantages of Supabase are not just this. When storing files in my projects, I mainly used AWS S3. I received images from the FE, changed the size, resolution, format, etc. of the photo internally through utility functions, then sent the photo to AWS S3 and received the photo URL to store in RDS. Supabase also basically provides Storage service like S3. The usage is very similar to S3, where you create folders to specify desired specific addresses to store files and immediately receive and use URLs through the URL return method provided by Supabase Storage.
AWS S3 Upload:
const uploadToS3 = async (file: File) => {
const s3Client = new S3Client({ region: location });
const uploadParams = {
Bucket: bucketName,
Key: `${folder}/${fileName}`,
Body: file,
ContentType: file.type,
};
const result = await s3Client.send(new PutObjectCommand(uploadParams));
const url = `https://${bucketName}.location.com/${folder}/${fileName}`;
return url;
};
Supabase Storage:
export async function uploadImage({ file, bucket, folder, customFileName }: UploadProps) {
const finalFileName = `${customFileName}.webp`;
const path = `${folder ? folder + "/" : ""}${finalFileName}`;
const { data, error } = await supabase.storage
.from(bucket)
.upload(path, file);
if (error) {
return { data: null, error, url: null };
}
const { data: urlData } = await supabase.storage
.from(bucket)
.getPublicUrl(path);
return { url: urlData.publicUrl, error: null };
}The code structure may look quite different, but reading the code, you can confirm that the basic structure of simply specifying file addresses, saving, and receiving URLs operates identically.
Performance Issues That May Occur When Migrating from AWS to Supabase
When I previously used AWS RDS and completed optimization settings for Connection, Pool, Region, etc., I recorded a Performance score of 100 points based on Lighthouse. After completing migration to Supabase, when I completed the same level of settings (region) as RDS, I was able to get the same Performance score as RDS.
However, generally when using Supabase, several performance issues may occur, and solutions from a different perspective than RDS are needed.
- Query overhead due to abstracted ORM
- Differences in Supabase's own Connection management methods
- Performance characteristic differences between PostgreSQL vs MySQL
- Architectural differences in CDN and network infrastructure
In reality, when referring to many articles and examples, it was not easy to find cases where performance issues occurred for these reasons, and I also did not experience these issues, but if there is a clear performance difference compared to RDS when using Supabase, I think it can be resolved based on the above reasons.
Conclusion
Supabase provides various services such as Storage and Auth in addition to databases in a user-friendly manner. If you are a user who was using AWS for basic DB hosting and file storage reasons, I recommend migration to Supabase. Realistically, for small companies or when conducting solo projects, it is overwhelming to keep up with AWS's extensive configuration-related knowledge, and cases of unexpected billing explosions can be easily found. Rather than only seeking famous services due to reasons of short history and lack of examples, I think experiencing new services like this can also be a good opportunity as a developer :)